
Aussehen
Bildgenerierung
Um Bilder aus Texteingaben zu generieren, lernt eine KI selbstüberwacht anhand bestehender Bilderdaten aus dem Internet.
Datenquelle
Besonders bei Bildern ist die Qualität der Eingangsdaten sehr wichtig. Im Grunde eigenen sich zwei Arten von Fotoquellen gut. Da sind zum einen Bilderdatenbanken im Internet,
welche Fotos mit Tags versehen und zum anderen beschreiben viele Seiten ihre Bilder, damit diese auch von Menschen mit Seheinschränkung wahrgenommen werden können. Dies ist teilweise sichtbar, wenn man mit der Maus über dem Bild verharrt:

Aufgabe
Prompts für Bilder sind in der Regel englisch und enthalten oft Abkürzungen, wie etwa hier bei PromptHero:
(8k, RAW photo, best quality, masterpiece:1. 2), (realistic, photo-realistic:1. 37), ultra-detailed, full body, 1 girl, solo, beautiful detailed sky, detailed cafe, night, beautiful detailed eyes, beautiful detailed lips, professional lighting, photon mapping, radiosity, physically-based rendering, extremely detailed eyes and face, beautiful detailed eyes, light on face, cinematic lighting, pink sweat shirt, white sneakers, jacket, 1girl, full body, full-body shot, see-through, looking at viewer, outdoors, ((blue hair))
a) Warum sind die Prompts auf Englisch und nicht Niederländisch oder Deutsch?
b) Warum verwendet obiges Beispiel so viele Wörter wie "masterpiece", "best quality" oder "8k", die das Aussehen scheinbar gar nicht beschreiben?
Selbstüberwachtes Lernen
Erkennst du, welches Tier sich hier verbirgt?

Das war gar nicht so schwer, aber wie sieht es mit

aus? Das ist schon fast unmöglich. Aber wenn wir uns ein solches Verrauschen eines Bildes in einer Reihe ansehen, wirkt es sehr machbar, immer das vorherige Bild zu rekonstruieren:

Unser Ziel ist es also eine KI zu erschaffen, die zu jedem verrauschten Bild ein nicht mehr ganz so verrauschtes Bild erschaffen kann. Nun gibt es im Internet selten so schöne Bildstrecken, in den ein Bild immer verrauschter wird. Daher verwenden wir einen Algorithmus, der die aus dem Internet geladenen Bilder schrittweise verrauscht:
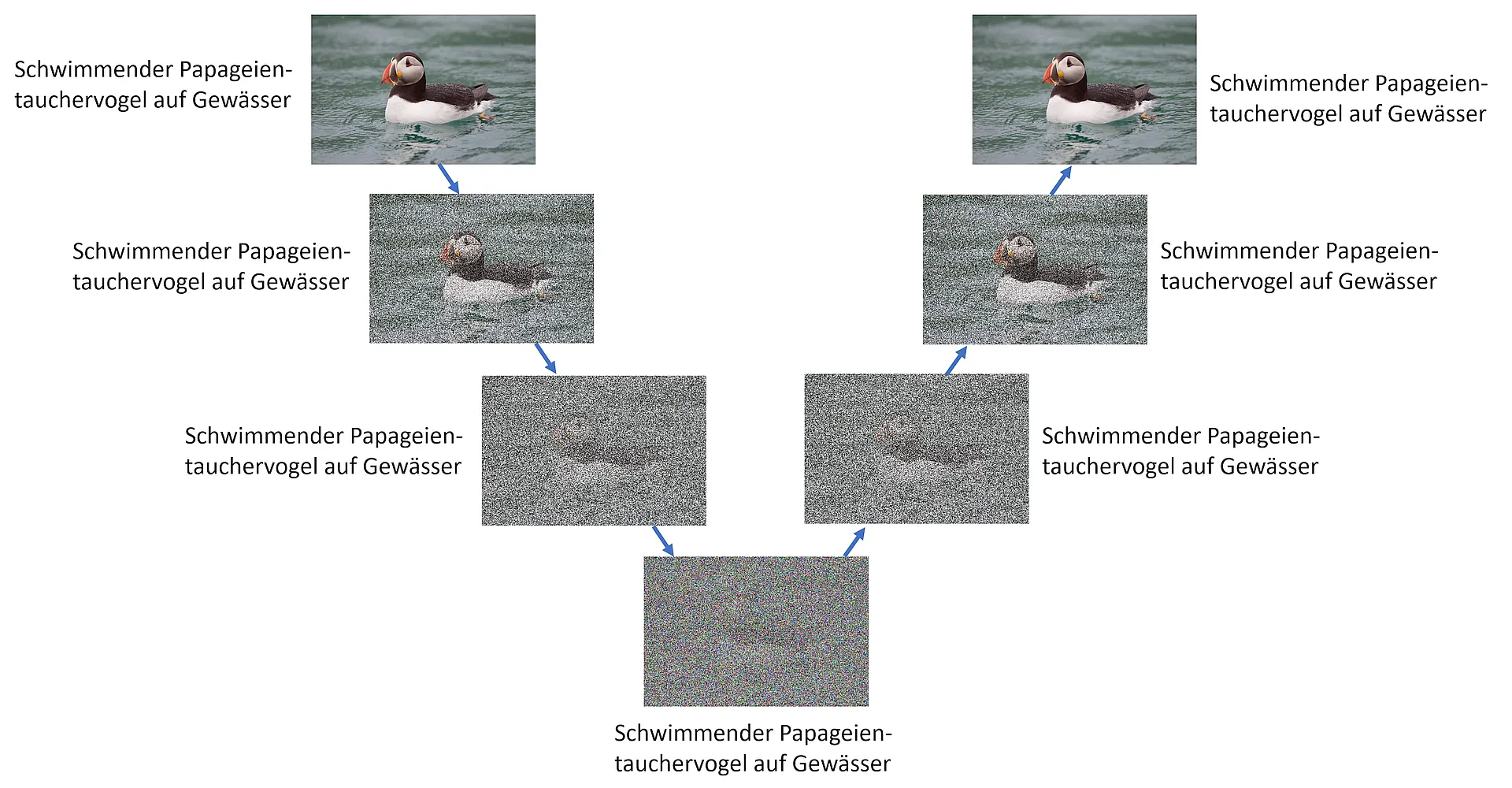
Jetzt können wir die stufenweise verrauschten Bilder mit der Beschriftung an die KI geben. Diese trainiert dann das stufenweise entrauschen der beschrifteten Bilder. Selbst, wenn es ganz unten scheinbar nur noch aus zufälligen Pixeln besteht.
Dadurch, dass die KI immer nur so kleine Schritte gehen muss, ist dies eine machbare Aufgabe. Müsste sie sofort vom untersten zum obersten Bild gelangen, wäre dies sehr viel komplizierter oder gar unmöglich.
Ist dieses Training abgeschlossen, kommt der Trick: Wir geben der KI jetzt ein zufälliges Bild aus lauter bunten Punkten (Seed) mit einer Beschriftung und fordern es auf, daraus das Bild herzustellen:
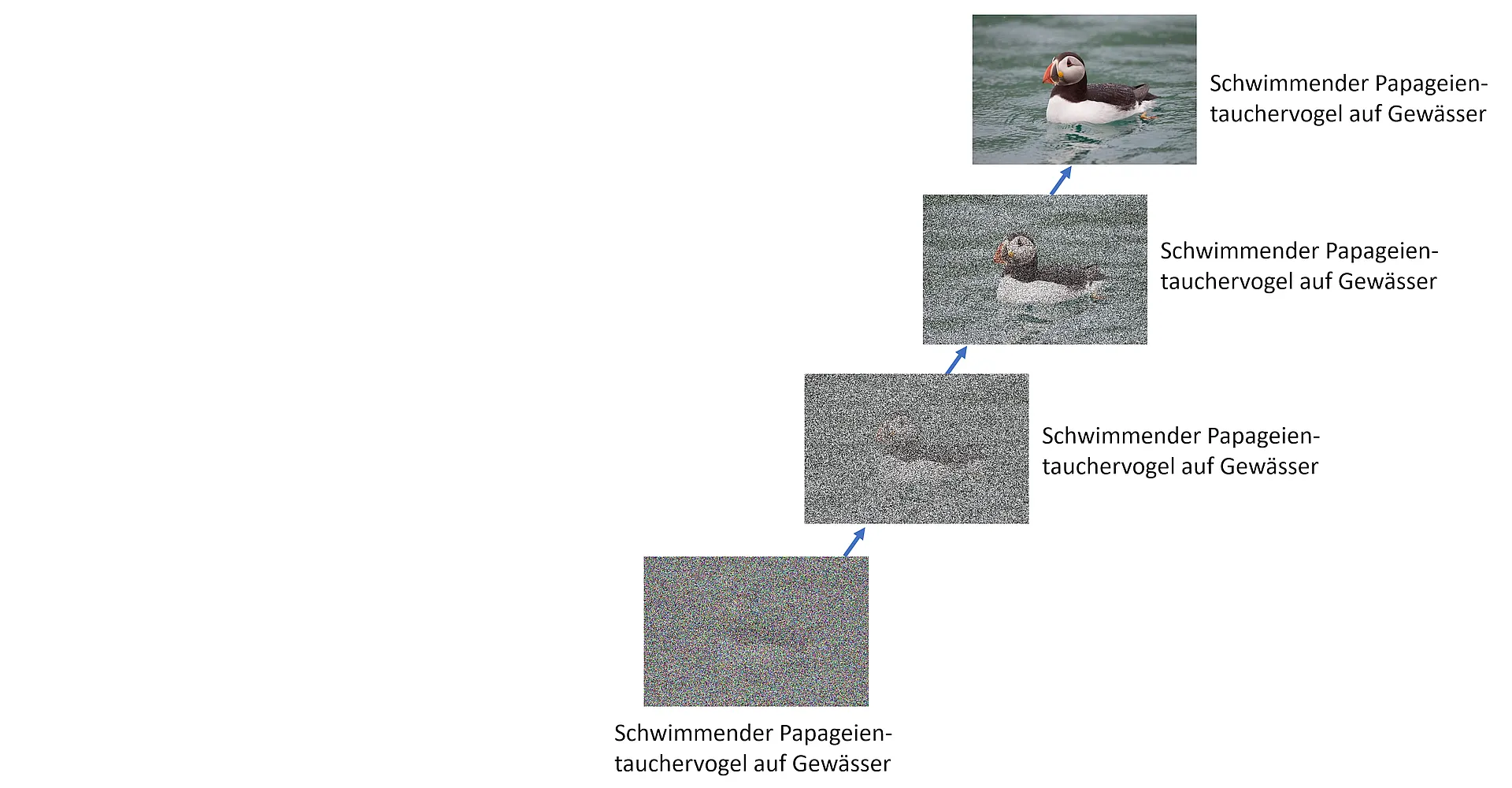
Die KI hat davor gelernt, wie sie aus scheinbar zufälligen Pixeln Stück für Stück das Bild herstellen kann und macht sich an die Arbeit. Da dies gern ausgegeben wird, um die Wartezeit für uns Menschen zu überbrücken, können wir uns das hier bei Midjourney ansehen:
Bestärkendes Lernen durch menschliche Rückkopplung

Ich denke wir sind uns alle einig, dass wir bei einem lachenden Hasen im Kindersitz eher an das rechte Bild als an ein Kind im Hasenkostüm gedacht haben. Da es aber sehr wenige Bilder von lachenden Hasen in Kindersitzen gibt, hat die KI sich einmal für ein Kind in einem Kindersitz entschieden (was es sehr oft als Foto gibt) und das dann als Verkleidung einem Hasen angenähert (was es auch öfters gibt) und im zweiten Fall hat es von einem Hasen aus gestartet und den wie eine Plüschfigur (was es auch manchmal gibt) in einem Kindersitz platziert.
Woher soll die KI nun aber wissen, was besser ist? Da kommen wir Menschen ins Spiel: Wurde eine Bilder-KI angelernt, so werden Menschen gebeten die Bilder einzuschätzen, um der KI eine Rückmeldung zu geben, ob das erzeugte Bild gut ist. Die KI kann diese Daten dann im nächsten Training nutzen, um bessere Bilder zu erzeugen.
Diese Rückmeldung kann sehr niederschwellig sein, indem man etwa wie bei Midjourney das beste Bild auswählt:

Oder ein differenziertes Feedback gibt und Schlagworte wie "verschwommen", "vier Finger" an ein entstelltes oder unschönes Bild schreibt.
Aufgabe
Woran kann Midjourney noch erkennen, welches Bild dir wohl am besten gefällt?
Aufgabe
Prompts für Bilder enthalten, wie etwa hier bei PromptHero, noch einen negativen Prompt, was zu vermeiden ist:
EasyNegative, paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, glans,extra fingers,fewer fingers,strange fingers,bad hand,signature, watermark, username, blurry, bad feet,bad leg, duplicate, extra limb, ugly, disgusting, poorly drawn hands, missing limb, floating limbs, disconnected limbs, malformed hands, blurry,mutated hands and fingers, EasyNegative, paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, glans,extra fingers,fewer fingers,strange fingers,bad hand,bad nails,signature, watermark, username, blurry, bad feet,bad leg
Ordne zu, welche Schlüsselbegriffe den Geschmack der Autor:in unterstreichen und welche ein schlechtes Bild verhindern sollen.
Bilder in natürlicher Sprache erstellen
Um Bilder in natürlicher Sprache zu erstellen, wird eine zweite KI verwenden, die den Prompt eines Menschen anpasst. Möchte ich etwa, dass DALLE-3 ein Bild zeichnet:
Mal mir ein Bild von einer Frau im roten Kleid in Dresden
So wird dies von ChatGPT-4 mit diesem sehr aufwendigen Prompt umgeformt zu:
Eine Frau mit europäischer Abstammung, die ein elegantes rotes Kleid trägt, steht in Dresden. Im Hintergrund sieht man die berühmte Frauenkirche und die Elbe. Die Szene findet an einem sonnigen Tag statt, und die Stadt strahlt in ihrer historischen Pracht. Die Frau steht auf einer Brücke über der Elbe, lächelt sanft und blickt auf die Stadtlandschaft. Das Bild vereint traditionelle deutsche Architektur mit einem modernen, stilvollen Element.
Diese präzise Formulierung unterstützt den Bildgenerierungsprozess.